Data Extraction of VINTAGE Wine CATALOGS
We developed an automated method to extract key features such as the wine name, bottle and case prices from 4,111 scanned Sherry Lehmann wine catalogs from the 1930’s to 1980’s. By experimenting with different optical character recognition (OCR) software, we chose Tesseract to build our algorithm. Using a randomly sampled subset of 100 images, we created a training set of three catalogs to train our algorithm over time. We selected 12 catalogs as a test set which all have similar page designs because our methods are based on certain characteristics. These characteristics range from at least one price column in a page and the wine name which is aligned horizontally to the left side of the bottle price. By using the training set we were able to identify similar characteristics that are in the form of a table in each catalog. The accuracy improved when we tried to cluster prices based on their right and top coordinates on the page. To quantify the accuracy rate we compared the string output of our algorithm with the true string value for each feature in our test set. Indeed, overall accuracy improved over time to reach 72%. In addition, the accuracy for each feature is wine name: 61%, bottle price: 81%, case price: 73%.
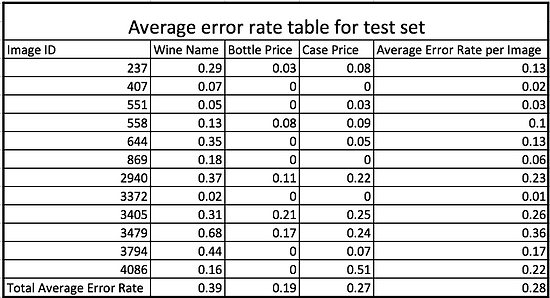
The table above reports the error rates for each image in our training set. The three types of error that we looked at by column are the following: wine name, bottle price and case price as well as the total error rate for each individual page. The three types of errors gave us a better idea of how well our algorithm is performing for each specific feature we are trying to capture.
Achieving a high accuracy rate from scanned wine catalogs using automated feature extraction requires different approaches. Our algorithm is just one approach that extracts specific features from wine scanned catalogs which have a similar outline. Although we can improve our algorithms accuracy rate over time, we have to consider our approach limitation and those factors which our algorithm will not be able to solve. Moreover, the extracted data might be used by those who are interested in further research and analysis of the wine industry. In addition, the code we have developed might be used by people who are interested in extracting data from any catalogs which have similar types of outlines.